
1. HBase元数据
HBase 表的元数据存储于 hbase:meta表中,HBase默认会 创建meta表,它属于系统命名空间hbase下面的表,.META. 结构如下

通过这个表可以清晰的查找表的region对应的元数据信息和服务器地址。
然而meta也是HBase里面的表,meta的数据的元数据存放在哪呢?HBase会使用ZooKeeper来存放
-ROOT-表的元数据。默认的路径是/hbase/root-region-server ,这个地址下面存放了-ROOT-表的地址的RegionServer地址,-ROOT-表的的结构和.META.表结构一致,唯一不同是,-ROOT-表存储的是.META.表的数据。-ROOT-表结构如下:

数据定位流程 : Zookeeper -> -ROOT- -> .META. -> User_Table
2. HBase HFile数据存储格式
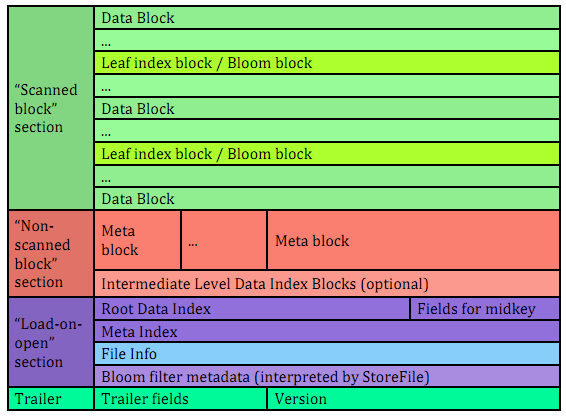
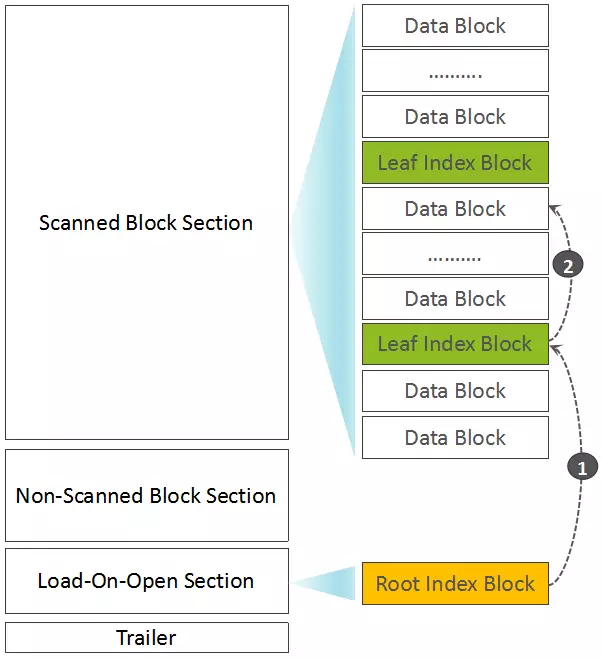
如果Root Block Index Chunk超出了预设大小,则输出位于Non-Scanned Block Section区域的Intermediate Index Block数据,以及生成并输出Root Index Block(记录Intermediate Index Block索引)到Load-On-Open Section部分。
详情可见官网
3. HBase 框架图
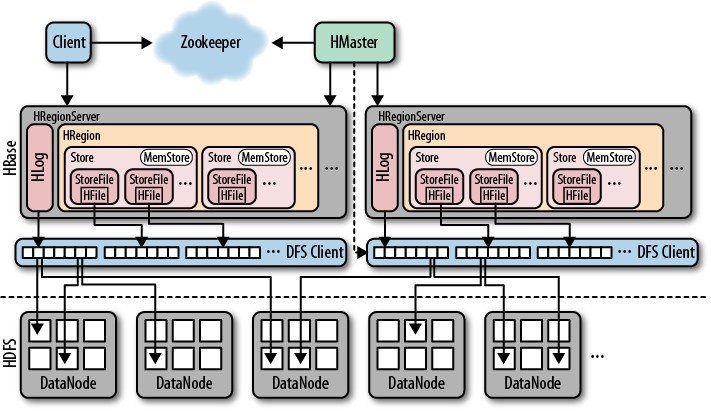
HMaster的作用
- 为Region server分配region。
- 负责Region server的负载均衡。
- 发现失效的Region server并重新分配其上的region到正常的RegionServer。
- HDFS上的垃圾文件回收。
- 处理schema更新请求。
HRegionServer作用
- 维护master分配给他的region,处理对这些region的io请求.
- 负责切分正在运行过程中变的过大的region。
上图没有提到的组件是BlockCache模块,每个RegionServer存在一个BlockCache,用户缓存查询的数据。
从上图可以看出
1. 每个Store对应一个HBase中的一个列簇,一个列簇有一个单独的Memstore,每个列簇对应多个HFile。
2. HBase主要通过Zookeeper来做集群监控。
4. HBase HFile Compact
当HBase底层的HFile越来越多,就会执行Compaction从操作,可以减少HFile数量,也可以删除一些标记删除的数据,从而减轻系统存储压力。
Compaction可以分为 minor Compaction 和 major Compaction
轻量级压缩minor Compaction
将符合条件的最早生成的几个Hfile合并成一个大的HFile文件,它不会删除标记为"删除"的数据的过期的数据,并且执行一次minor合并操作后还会有多个storefile文件。
重量级压缩major Compaction
把所有的HFile合并成单一的HFile文件,在文件合并期间,会删除标记为删除标记的数据和过期失效的数据,同时会阻塞所有客户端对该操作所属的region的请求直到合并请求完毕。最后删除已经合并过的HFile小文件。
参数控制:
| 参数名 | 配置项 | 默认值 | 解释 |
| majorcompaction | hbase.hregion.majorcompaction | 1天 | 设置系统进行一次MajorCompaction的启动周期,如果设置为0,则系统不会主动触发MC过程。 |
| minFilesToCompact | hbase.hstore.compactionThreshold | 3 | 表示至少需要三个满足条件的store file时,minor compaction才会启动 |
| hbase.hstore.compaction.max.size | 合并的文件大小最大是多少,超过此大小的文件不 能参与合并 | ||
| maxFilesToCompact | hbase.hstore.compaction.max | 10 | 表示一次 minor compaction中最多选取10个store file |
优化建议:
hbase.hstore.compactionThreshold 设置不能太大,默认是 3 个;
设置需要根据 Region 大小确定,通常可以简单的认为 hbase.hstore.compaction.max.size = RegionSize / hbase.hstore.compactionThreshold
5.HBase HFile Spilt
HBase 触发Split
HBase中共有3种情况会触发HBase的split,分别是:
1.当memstore flush操作后,HRegion写入新的HFile,有可能产生较大的HFile,HBase就会调用CompactSplitThread.requestSplit判断是否需要split操作。
2.HStore刚刚进行完compact操作后有可能产生较大的HFile,当满足HBase的某一分裂策略后就会进行split操作。
3.当HBaseAdmin手动发起split时,也会触发split操作。
当HFile的大小超过阈值时(hbase.hregion.max.file.size = 256M),会触发HBase的文件分裂的流程。
hbase.regionserver.regionSplitLimit=1000 设置一个RegionServer的Region上限个数。
注意:
hbase.hregion.max.filesize不宜过大或过小, 生产高并发运行下,最佳大小5-10GB!关闭某些重要场景的hbase表的major_compact!
在非高峰期的时候再去调用major_compact,这样可以减少split的同时,显著提供集群的性能,吞吐量、非常有用。
HBase Split策略
- IncreasingToUpperBoundRegionSplitPolicy
region split的计算公式是:regioncount^3 * 128M * 2,当region达到该size的时候进行split。
- ConstantSizeRegionSplitPolicyo
0.94.0之前该策略是region的默认split策略,0.94.0之后region的默认split策略为IncreasingToUpperBoundRegionSplitPolicy,当region size达到hbase.hregion.max.filesize(默认10G)配置的大小后进行split
- DisabledRegionSplitPolicy
该策略是直接禁用了region的自动split。
- KeyPrefixRegionSplitPolicy
根据rowKey的前缀对数据进行分组,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在进行region split的时候会分到相同的region中。
- DelimitedKeyPrefixRegionSplitPolicy
保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
设置策略demo
hbase.regionserver.region.split.policy org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy hbase-default.xml
6.HBase读写流程
写入流程
1.首先写入WAL日志,以防Crash
2. 写入MemStore缓存,即写缓存,由于是内存写入所以速度比较快。
3.立马返回客户端写入完成
4.当Memstore满时,从Memstore刷新到HFile,磁盘的顺序读写速度非常快,并记录下最后一次最高的sequence号,这样系统能知道哪些记录已经持久化,哪些没有。
读取流程
1.从Memstore中读取数据
2.读取BlockCache 中查找可能被缓存的数据
3.访问HFile ,合并所有的数据返回客户端
7.HBase BlockCache 和 Memstore
模块JVM堆内存默认比例
memstore[40%] blockcache[40%] other[20%]
blockcache比例设置
hfile.block.cache.size=0.3 (堆内存的0.3)
memstore比例设置
hbase.regionserver.global.memstore.size (region 单个 memstore 内存占比 默认0.4)
hbase.regionserver.global.memstore.upperLimit=0.6。
一个Regionserver上有一个BlockCache和N个Memstore,它们的大小之和不能大于等于heapsize * 0.8,否则HBase不能正常启动。( blockcache + memstore 内存比列占堆内存比列<80% 才能启动。)
每个Region都有自己的MemStore,当大小达到了上限(hbase.hregion.memstore.flush.size,默认128MB),会触发Memstore刷新。
BlockCache 组成
- Single(0.25):如果一个Block第一次被访问,则放在这一优先级队列中,占;
- Multi(0.5):如果一个Block被多次访问,则从Single队列移到Multi队列中;
- InMemory(0.25):如果一个Block是inMemory的,则放到这个队列中。
8.HBase WAL
HBase的Write Ahead Log (WAL)提供了一种高并发、持久化的日志保存与回放机制。每一个业务数据的写入操作(PUT / DELETE)执行前,都会记账在WAL中。如果出现HBase服务器宕机,则可以从WAL中回放执行之前没有完成的操作。
对于不太重要的数据,可以在Put/Delete操作时,通过调用Put.setWriteToWAL(false)或Delete.setWriteToWAL(false)函数,放弃写WAL日志,以提高数据写入的性能。
9.建表属性
(1) BLOOMFILTER create ‘table’,{BLOOMFILTER =>’ROW’}
启用布隆过滤可以节省读磁盘过程,可以有助于降低读取延迟,行键的哈希在每次插入行时将被添加到布隆
(2) VERSIONS create 'table',{VERSIONS=>'2'}默认是1 这个参数的意思是数据保留1个 版本,如果认为我们的老版本数据对我们毫无价值不需要保留这么多,且更新频繁,那将此参数设为1 能节约2/3的空间
(3) COMPRESSION create 'table',{NAME=>'info',COMPRESSION=>'SNAPPY'}这个参数意思是该列族是否采用压缩,采用什么压缩算法
(4) hbase 表预分区—-手动分区 create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡
10.客户端优化
(1)Auto Flush
通过调用HTable.setAutoFlushTo(false)方法可以将HTable写客户端自动flush关闭,这样可以批量写入数据到HBase,而不是有一条put就执行一次更新,只有当put填满客户端写缓存的时候,才会向HBase服务端发起写请求。默认情况下auto flush是开启的。
(2)Write Buffer
通过调用HTable.setWriteBufferSize(writeBufferSize)方法可以设置HTable客户端的写buffer大小,如果新设置的buffer小于当前写buffer中的数据时,buffer将会被flush到服务端。其中,writeBufferSize的单位是byte字节数,可以根基实际写入数据量的多少来设置该值。
(3)批量写
通过调用HTable.put(Put)方法可以将一个指定的row key记录写入HBase,同样HBase提供了另一个方法:通过调用HTable.put(List<Put>)方法可以将指定的row key列表,批量写入多行记录,这样做的好处是批量执行,只需要一次网络I/O开销,这对于对数据实时性要求高,网络传输RTT高的情景下可能带来明显的性能提升。(4)多线程并发写
在客户端开启多个 HTable 写线程,每个写线程负责一个 HTable 对象的 flush 操作,这样结合定时 flush 和写 buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被 flush(如1秒内),同时又保证在数据量大的时候,写 buffer 一满就及时进行 flush。(5)批量读
通过调用 HTable.get(Get) 方法可以根据一个指定的 row key 获取一行记录,同样 HBase 提供了另一个方法:通过调用 HTable.get(List) 方法可以根据一个指定的 row key 列表,批量获取多行记录,这样做的好处是批量执行,只需要一次网络 I/O 开销,这对于对数据实时性要求高而且网络传输 RTT 高的情景下可能带来明显的性能提升。 (6) 客户端缓存scan的扫描缓存setCaching(int caching) 设置的值为每次rpc的请求记录数.
scan的扫描缓存 scan.setCacheBlocks(false); 设置请求的记录是否缓存到服务端的BlockCache,MR时需要设置为false